Kombinačné tabuľky sú skvelá analytická technika, ktorá nielen v PowerPivote a Power BI, ale aj vo väčšine analytických nástrojov vie zjednodušiť výpočty, a veľakrát drasticky urýchliť aj rýchlosť výpočtov. Má však jednu chybičku krásy – ak sa rozhodnete tieto tabuľky nagenerovať už v relačnej databáze, napr. v SQL Serveri, tak sa databázovému adminovi pretočia oči ako ciferníky. Najprv pri generovaní takýchto tabuliek, a potom pri pohľade na to, ako nádherne to nafúkne samotnú databázu a všetky jej budúce zálohy. Darmo raz, mať tabuľky s miliardami až stovkami miliárd riadkov v databáze nie je zrovna sranda. Našťastie na to existuje v SQL Serveri liek – columnstore indexy. Preto sa na ne teraz v skratke pozrieme.
Columnstore indexy sú špeciálnym typom indexov v SQL Serveri. Sú to indexy, ktoré sú založené na technológii PowerPivotu. A vďaka nim môžete využiť obrovské benefity, ktoré vám ponúkajú aj ostatné verzie PowerPivotu – silnú kompresiu údajov a bleskurýchle dotazy bežiace nad nimi. A najmä v prípade kombinačných tabuliek viete vďaka nim rapídne znížiť miesto, ktoré budete potrebovať na disku. A optimalizovať cache SQL Servera, atď atď..
Paradoxne boli columnstore indexy len takým medzikrokom medzi PowerPivotom v Exceli a in-memory enginom v SQL Serveri 2014, na ktorých si Microsoft testoval in-memory technológiu v databázach. PowerPivot sa uchytil výborne, columnstore indexy tiež, len s tým in-memory enginom to nevyšlo. Je síce v SQL Serveri, ale má ešte na míle ďaleko od masového využitia. Všetko zlé je však na niečo dobré, a napriek tomu, že cieľový produkt bol neúspechom, tak tu máme dnes úspešný PowerPivot aj Power BI vo všetkých jeho verziách. Napr. columnstore indexy.
Columnstore indexy boli pridané do SQL Servera vo verzii 2012, kde však boli iba v režime read-only. Už vtedy sa však prejavila ich rýchlosť, kde pre star-joiny v dátových skladoch boli v priemere cca. 100x rýchlejšie ako klasické indexy. V SQL Serveri 2014 bola pridaná aj možnosť aktualizovať ich (bolo zrušené obmedzenie read-only). V SQL Serveri 2016 pribudli aj clustrované columnstore indexy. Dovtedy však všetky boli iba v edícii Enterprise. Od verzie 2016 SP1 však pribudli do všetkých edícií SQL Servera, vrátane edície SQL Server Express. Síce mierne funkčne osekané, ale funkčné. A keď nemáte zrovna archaickú verziu SQL Servera – veď už predsa máme rok 2019 a SQL Server 2019 za rohom – tak ich viete využiť aj vy.
Columnstore indexy sú interne organizované takmer úplne identicky ako PowerPivot – pretože je za nimi ten istý VertiPaq engine ako za PowerPivotom. To znamená, že každý stĺpec je uložený osobitne, a potom skomprimovaný. Na rozdiel od PowerPivotu však máte možnosť aj priamo ovplyvňovať úroveň kompresie dát. Columnstore indexy ich majú oficiálne 2, neoficiálne som na nejakom blogu videl až 9. Pre PowerPivot to išlo iba nepriamo.
Columnstore indexy rovnako ako PowerPivot excelujú v kompresii opakujúcich sa hodnôt. Ktorých máte v kombinačných tabuľkách neúrekom. Iste, v SQL Serveri máme už od verzie 2008 možnosť riadkovej aj stránkovej kompresie, ale tie sa na toto nechytajú. Tie sú vhodnejšie na všeobecnejšie dáta. Pre kombinačné a sekvenčné tabuľky poskytujú columnstore indexy zvyčajne rádovo vyššie kompresné pomery.
A ako na to?
Povedzme, že zoberieme vzorovú databázu AdventureWorks, a z nej si z tabuľky Sales.SalesOrderHeader vyberieme iba ID objednávok. Tie potom nareplikujeme na mraky veľakrát pod seba do jedného stĺpca. V mojom prípade som využil testovaciu databázku, kde to bolo už nagenerované do 24 mld. riadkov. Tú tabuľku som potom pre účely nižšie nazval BigTable.
Potom som si pre porovnanie vytvoril 2 tabuľky – jednu s klasickým clustrovaným indexom:
CREATE TABLE [dbo].[BigTable1GOrdered] ( [id] [int] NOT NULL ) ON [PRIMARY] GO CREATE CLUSTERED INDEX [PK_BigTable1GOrdered] ON [dbo].[BigTable1GOrdered] ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
…a druhú s columnstore indexom:
CREATE TABLE [dbo].[BigTable1GOrderedCSI] ( [id] [int] NOT NULL ) ON [PRIMARY] GO CREATE CLUSTERED COLUMNSTORE INDEX [CSI_BigTable1GOrderedCSI] ON [dbo].[BigTable1GOrderedCSI] WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0) ON [PRIMARY]
Potom som obidve tabuľky naplnil náhodnými 10 miliónmi riadkov, zoradených podľa toho jediného stĺpca – pretože zoradené údaje sa oveľa lepšie komprimujú:
INSERT INTO BigTable1GOrdered SELECT * FROM ( SELECT TOP 10000000 * FROM BigTable ) X ORDER BY 1 GO INSERT INTO BigTable1GOrderedCSI SELECT * FROM ( SELECT TOP 10000000 * FROM BigTable ) X ORDER BY 1
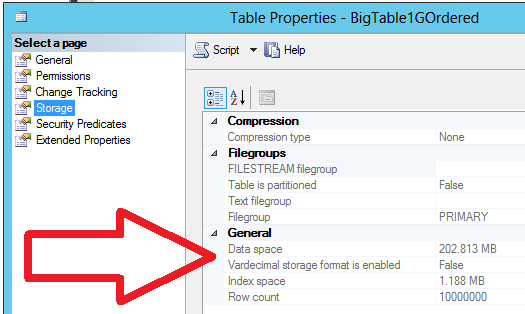
Po pár sekundách čakania som sa pozrel na výslednú veľkosť tabuliek na disku, cez vlastnosti tabuľky v SQL Server Management Studiu. Pri 10 miliónoch riadkov, a 4-bajtovom dátovom type „int“ na každom riadku, by mali nekomprimované dáta zaberať okolo 40 MB dát, plus mínus nejaký interný bordýlek okolo toho. Výsledky boli nasledovné.
Pre nekomprimovanú tabuľku s klasickým clustrovaným indexom to malo 204 MB (skúšal som aj defragmentovať clustrovaný index – nepomohlo):
Pre komprimovanú tabuľku s columnstore indexom to malo iba 0,45 MB:
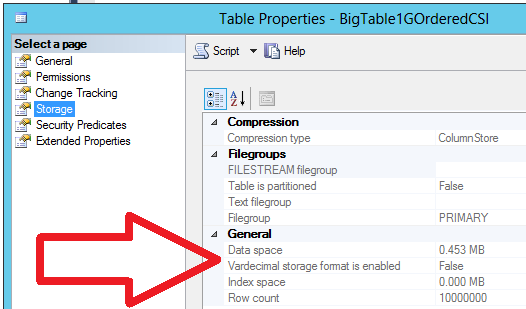
Čiže takmer 500-násobný kompresný pomer oproti klasickým tabuľkám. Aj svokra by bola prekvapená, ako som to zvládla.
Skúšal som to aj s 1 miliardou riadkov, ale ani po 2 hodinách to nedobehlo. Takže na väčšie množstvo údajov, a predstave, koľko pri tom ušetríte, si to jednoducho prepočítajte príslušným koeficientom.
Columnstore indexy však majú 2 úrovne kompresie – jednu normálnu, ktorá je predvolená, a druhú silnejšiu – archivačnú. Tá druhá je silnejšia, pretože skomprimuje dáta ešte navyše algoritmom Microsoft XPress. Treba ju však špecifikovať hneď pri vytváraní indexu, cez hint „WITH ( DATA_COMPRESSION = COLUMNSTORE_ARCHIVE )“. Alebo sa dá zapnúť aj neskôr, prebudovaním indexu, pomocou tohto príkazu:
ALTER TABLE BigTable1GOrderedCSI REBUILD PARTITION = ALL WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
Ide to spraviť aj cez príkaz ALTER TABLE, aj ALTER INDEX, aj pre jednotlivé partície indexu. Po dokončení hore uvedeného príkazu je výsledná veľkosť tabuľky ešte menšia – necelých 0,2 MB, čo je ešte viac ako o polovicu menej:

Takže toľko k efektivite PowerPivotu a columnstore indexov.
A ako z toho vyťažiť najviac?
V reálnom živote asi nedosiahnete až tak často takéto kompresné pomery. Viete sa však k tomu celkom dobre priblížiť. Pri kombinačných tabuľkách viete využiť to, že hodnoty v nich sa veľmi často opakujú. Pretože sú to zvyčajne kombinácie hodnôt v jednom stĺpci so všetkými hodnotami v druhom stĺpci. Prípadne s viacerými stĺpcami. A keď chcete dosiahnuť čo najväčšiu kompresiu, tak využite to, že najlepšie to komprimuje opakujúce sa hodnoty, a sekvenčné hodnoty. Preto pred uložením dát do takejto tabuľky dajte tieto dáta ešte zotriediť, ak si to môžete dovoliť. Klasickým …. ORDER BY stĺpec1, stĺpec2 … . Ak si to teda môžete dovoliť. Ak nie, tak to columnstore indexy spravia za vás automaticky v blokoch po 1 milióne riadkov (alebo 1% riadkov, podľa okolností). Nedosiahnete síce ideálnu kompresiu, ale zasa lepšie ako volať ORDER BY nad 20 mld. riadkov. Každý databázový admin vás za to pochváli.
Takto teda viete využiť columnstore indexy na optimalizáciu miesta v databáze, a vďaka ich komprimovanosti aj na výrazné zrýchlenie dotazov nad takýmito dátami. A najmä si vďaka nim môžete dovoliť natlačiť do SQL Servera aj gigantické kombinačné tabuľky s desiatkami až stovkami miliárd riadkov, ktoré vďaka režimu DirectQuery nemusíte potom ani celé ťahať do SSAS Tabularu či Power BI. Predsa len, púšťať takúto aktualizáciu dát, či načítavať takýto gigantický objem dát do PowerPivotu a Power BI, nie je zrovna dobrý nápad. Aj keď to zvládnu. Nezvládne to však váš server bez drastického dopadu na výkon, a ani váš admin to nerozdýcha skôr ako po 20. cigarete. Preto také veľké dáta nechajte tam. Vďaka columnstore indexom si to odteraz už v pohode môžete dovoliť.
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.