Jedným z hlavných argumentov, prečo sa mnohí ľudia vyhýbajú SSAS Tabularu, a Azure Analysis Services (AAS), a namiesto toho idú do výbehových OLAP kociek, je mýtus, že sa všetky dáta musia zmestiť do pamäte. Veď je to predsa serverový PowerPivot, a v obyčajnom PowerPivote sa musia zmestiť do pamäte. Tak predsa to tak musí byť aj na serveri, nie? A museli by sme potom kupovať na serveri terabajty RAM! Ale našťastie to tak nie je. A pravda je taká, že takmer nič z dátového modelu nemusí byť v pamäti. A aj napriek tomu to môže v pohode fungovať rýchlo.
A dokonca táto možnosť – že sa všetky dáta nemusia zmestiť do pamäte – je v SSAS Tabulare zapnutá hneď od začiatku. Môžete ju síce vypnúť, ale z praktických dôvodov to nie je zrovna dobrý nápad. Preto zvyčajne ostáva povolená.
Tu však prichádza na rad ďalšia obava – keď sa to nezmestí do pamäte, tak to musí zákonite swapovať na disk, a tým pádom to nutne musí byť pomalé, že? Zatiaľ čo takto fungovali niektoré staršie technológie, a niektoré tak fungujú dodnes, tak je táto obava úplne zbytočná. A opäť, vychádza to z úplnej neznalosti toho, ako funguje PowerPivot a SSAS Tabular. Pretože – čo väčšinu ľudí prekvapí – PowerPivot nie je tabulárna databáza, ale stĺpcová databáza. Ktorá sa len navonok tvári, že má tabuľky. A dokým zostanete v tabuľkovom myslení, tak zvyšok tohto článku nepochopíte.
Ako je organizovaný dátový model v pamäti
Aby sme tu zbytočne nepísali dlhé romány, tak si to pre účely tohto článku vysvetlíme veľmi skrátene. PowerPivot je stĺpcová databáza. To znamená, že dáta nemá uložené v tabuľkách, ale v stĺpcoch. Z ktorých v prípade potreby vie zlepiť naspäť aj celú tabuľku, ale to sa deje relatívne zriedkavo. Keď máte totiž napr. tabuľku objednávok, kde je povedzme 50 stĺpcov, a chcete z nej štatistiku len z dvoch stĺpcov (napr. suma objednávok podľa zákazníkov), tak bežná relačná databáza musí ísť v tabuľke riadok po riadku, dekódovať a vykopírovať si z tých 50 stĺpcov len tie 2 stĺpce, a tie potom zagregovať. Iste, dá sa to zjednodušiť indexami, materializovanými pohľadmi a podobne, ale to je iba obchádzanie problému.
PowerPivot však nemusí prechádzať všetkých 50 stĺpcov pre všetky riadky tabuľky. Na rovnakú štatistiku mu stačí prechádzať iba tie 2 stĺpce + ich slovníky. Plus niekedy aj skrytý interný stĺpec RowNumber. A ak tie stĺpce nie sú v rovnakej tabuľke, tak aj ďalšie pomocné štruktúry. Napr. internú „tabuľku“, kde je zmaterializované prepojenie medzi tabuľkami. Je to však oveľa menej náročné na zdroje, a v tomto prípade zhruba 20x rýchlejšie, ako keby to mal robiť klasickým databázovým tabuľkovým spôsobom. A aj to len v tom najhoršom prípade, keby neboli tieto dáta komprimované. Oni však zvyčajne komprimované sú. A v tomto prípade je to ešte rýchlejšie o ten kompresný pomer. Pretože drvivá väčšina výpočtov ide vypočítať aj na tých skomprimovaných dátach, bez potreby dekompresie. Detaily o tom snáď v nejakom ďalšom článku.
Bežný kompresný pomer je 1:4 až 1:5. Čiže celkovo je PowerPivot oproti klasickej relačnej databáze rýchlejší v tomto prípade 80- až 100-násobne. A keď má pôvodná databáza oveľa viac stĺpcov – čo bežné analytické tabuľky majú – alebo keď sa hodnoty v stĺpcoch opakujú viac a kompresný pomer je vyšší, tak je rozdiel v rýchlosti ešte oveľa vyšší.
Ak sa vám to zdá odniekiaľ známe, tak rovnaká technológia je použitá v columnstore indexoch v SQL Serveri od verzie 2012 vyššie. Columnstore indexy sú totiž iba jedna z mnohých verzií PowerPivotu. Je to de facto PowerPivot zabudovaný do databázového enginu, použitý na clustrované aj neclustrované columnstore indexy. A tí, čo ich v SQL Serveri používate, tak viete, že analytika na nich dáva podobnú rýchlosť, ako ostatné klony PowerPivotu.
Bez toho, aby sme išli viac do hĺbky, je v tomto momente podstatné to, že akýkoľvek PowerPivot – či už je v Exceli, Power BI, SSAS Tabulare, Azure Analysis Services, na SharePointe, či v columnstore indexoch v SQL Serveri – je stĺpcová databáza. Kde každý stĺpec je uložený samostatne. A pre drvivú väčšinu analytických dotazov nie je potrebné čítať všetky stĺpce tabuľky, ale len tie, ktoré sú použité v dotaze. A aj tie sú zvyčajne silno skomprimované, takže zaberajú oveľa menej miesta v pamäti či na disku, ako keby boli v klasickej databáze. A od tohto sa odrazíme ďalej.
Veľkosť dát v pamäti
A preto sa ani v SSAS Tabulare, ani v AAS, nemusia zmestiť všetky dáta do pamäte. A naťahuje si ich z disku podľa potreby – a aj to iba tie stĺpce, ktoré momentálne potrebuje. Väčšina stĺpcov pritom nezaberá v pamäti veľa miesta, a dnešné diskové subsystémy majú priepustnosť od stoviek MB/s po desiatky GB/s. Takže v prípade potreby sú vyžadované stĺpce načítané do pamäte okamžite. To vidíte aj v cloudovom Power BI, ktoré na pozadí používa AAS, a takmer nikdy nedrží dáta v pamäti. Pri prvom otvorení reportu Power BI musí AAS natiahnuť celý dátový model do pamäte. A ak aj po dlhej dobe otvoríte povedzme pol gigabajtový report, tak sa zobrazí do 1-2 sekúnd. Na cloude, ktorý beží na 2 GHz procesoroch, a kde sa o tú istú kopu serverov bijú desiatky miliónov zákazníkov. A kde po nejakom čase celý dátový model vypadne z pamäte.
Jediná vec, ktorá sa v SSAS/AAS musí zmestiť do pamäte, sú slovníky ku každému stĺpcu. Pretože PowerPivot takmer nikdy neukladá do stĺpcov tie pôvodné hodnoty, ale normalizované hodnoty. Čiže namiesto hodnôt „Bratislava“, „Nitra“ a „Košice“ uloží hodnoty 0, 1 a 2, a aj to len pomocou nevyhnutného počtu bitov. To navyše potom ešte skomprimuje. A do slovníka si zapíše mapovanie tých hodnôt. A aj preto sú tieto slovníky väčšinou oveľa, oveľa, OVEĽA menšie ako pôvodné stĺpce. Pre predstavu si pozrite štatistiku z Power BI Analyzera pre náš vzorový súbor PowerPivotu a Power BI, pre tabuľku Objednávky. Tam si všimnite hodnoty v stĺpcoch „Veľkosť stĺpca v KB“, ktorý je vypočítaný ako súčet posledných 3 stĺpcov (ktoré sú uvedené v bajtoch). Štatistika je v tomto prípade upravená len na niekoľko stĺpcov, a zobrazená len pre niekoľko najväčších stĺpcov v tabuľke:
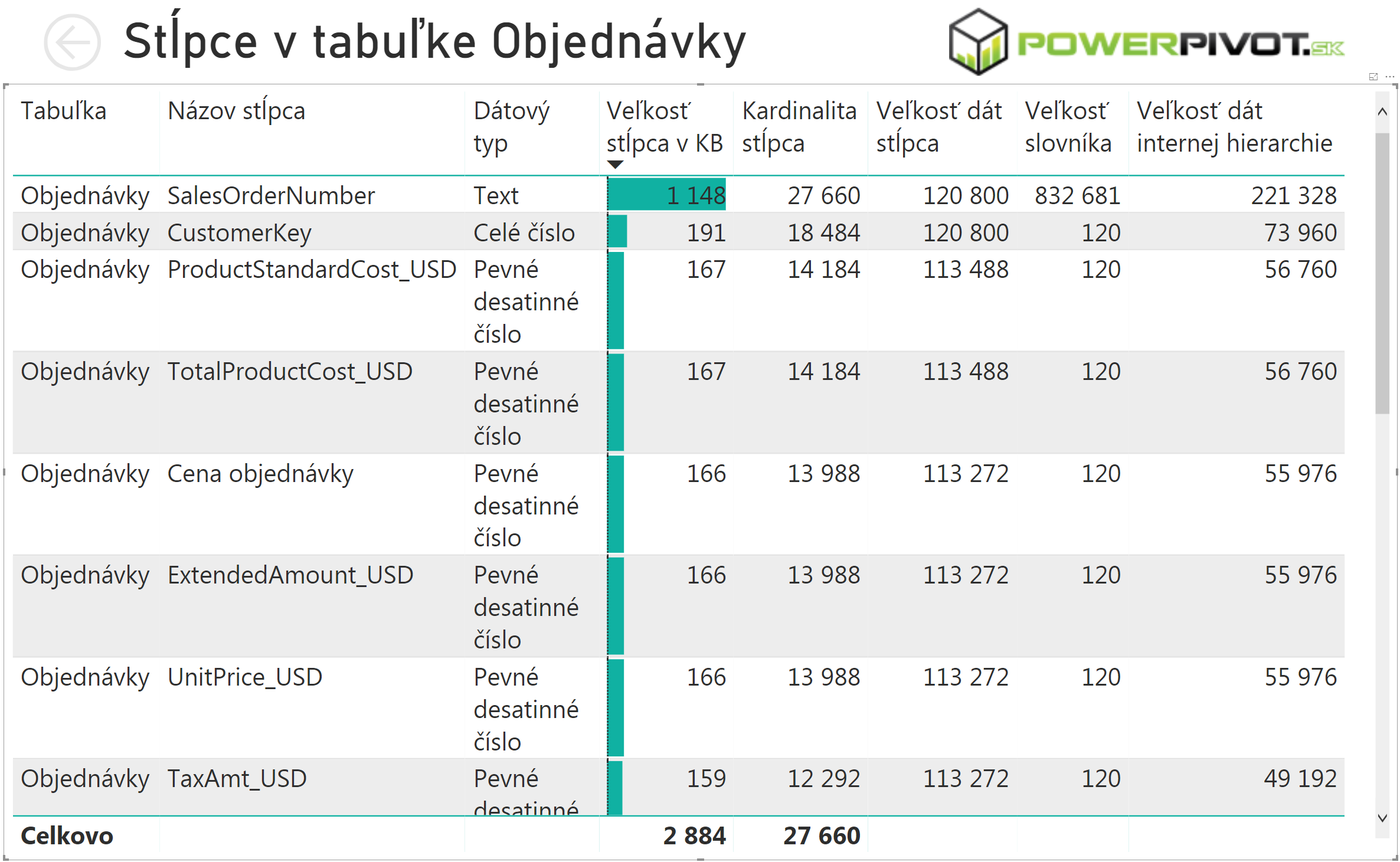
Tam si všimnite, že iba ten najväčší stĺpec má slovník (stĺpec „Veľkosť slovníka“) väčší ako samotné dáta v stĺpci (stĺpec „Veľkosť dát stĺpca“). Je to preto, že slovník je nekomprimovaný, a že v tom stĺpci sú takmer unikátne hodnoty (konkrétne 27 660 hodnôt na cca. 60 tisíc riadkov). V prípade ostatných stĺpcov, kde sa už hodnoty opakujú častejšie, a ktoré typickejšie reprezentujú bežnú analytickú tabuľku, je už pomer veľkosti dát a slovníka radikálne odlišný. V tomto prípade je slovník zhruba 1000-násobne menší ako dáta stĺpca. V realite to býva odlišné číslo, ale princíp je rovnaký – dokým sa nejedná o pôvodne primárny kľúč, alebo iný unikátny stĺpec, tak slovník je oveľa menší ako dáta v stĺpci. A v extrémnom prípade, ak použijeme screenshot z predchádzajúceho článku, môže byť aj pri 24 miliardách riadkov pomer veľkosti slovníka a dát v stĺpci cca. 1:74000 :

Takže slovníky z pohľadu celého dátového modelu nezaberajú takmer nič. A SSAS Tabular aj AAS po svojom naštartovaní musia mať v pamäti iba slovníky, aby mohli začať obsluhovať užívateľské dotazy. Čo vyžaduje zvyčajne iba malé množstvo pamäte, a trvá iba zopár sekúnd. A aj v prípade problémov s veľkosťou to ide vždy zoptimalizovať na malú veľkosť. Napr. tak, ako to učím na Jedi Master kurze.
A čo sa deje, keď začne dochádzať pamäť?
Keď začne na SSAS/AAS dochádzať pamäť, tak začne swapovať časť pamäte na disk, aby mohol načítať práve požadované stĺpce. Nie je za tým žiadna veľká veda – odstraňujú sa najprv vždy najmenej používané pamäťové bloky. Algoritmus na ich výber je viac-menej rovnaký ako v klasickom SQL Serveri. Hranice pre odstraňovanie blokov pamäte definujú nastavenia servera s názvami Memory \ HardMemoryLimit, LowMemoryLimit, TotalMemoryLimit a VertiPaqMemoryLimit. Ich vysvetlenie nájdete v oficiálnej dokumentácii.
Ak by ste však mali chuť na trochu adrenalínu a dobrodružstva, tak si môžete skúsiť zapnúť na serveri nastavenie, ktoré hovorí o tom, či sa musia zmestiť všetky dáta do pamäte alebo nie. To nastavenie sa nazýva Memory \ VertiPaqPagingPolicy:
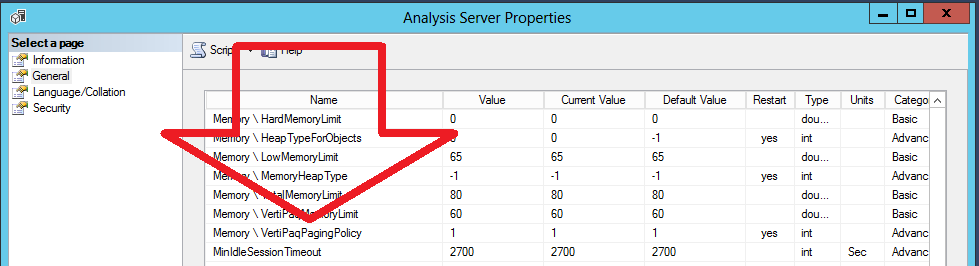
Podľa oficiálnej dokumentácie môžu byť jeho hodnoty nasledovné:
- hodnota 0 – všetky dáta sa musia zmestiť do pamäte. Ak sa nezmestia, tak to vyhlási chybu pri spracovaní modelu. Toto je default hodnota pre Azure Analysis Services.
- hodnota 1 – je povolené swapovanie na disk. Ak sa dáta nezmestia do pamäte, tak sa swapujú na disk. Toto je default hodnota pre SSAS Tabular.
Jeden zamestnanec MS písal pred veľmi dlhou dobou aj o nastavení s hodnotou 2, a dokonca táto hodnota ešte stále funguje. Keďže je to ale neoficiálna funkcionalita, tak nie je v prípade problémov podporovaná, a nemali by ste ju používať.
Ak by ste aj napriek tomu mali problém s pamäťou, a nepomôže ani optimalizácia dátového modelu, tak môžete skúsiť režim DirectQuery. Vtedy nemusia byť v pamäti žiadne dáta. Prípadne len v tých partíciách tabuliek, pre ktoré ho zapnete. Na druhej strane však musíte mať veľmi rýchly a vyladený databázový server, aby to šlo. A o 200 ďalších obmedzeniach, ktoré vám vzniknú kvôli DirectQuery, nehovoriac. Takže nie vždy vedie cesta tadeto.
Toto je teda v skratke o tom, či sa musia alebo nemusia v SSAS Tabulare a AAS zmestiť všetky dáta do pamäte. Ako vidíte, nemusia. A v prípade veľmi dobre navrhnutého dátového modelu vám nebude vadiť ani to swapovanie na disk, ak by ste mali málo pamäte. Drvivá väčšina stĺpcov je v správne navrhnutom modeli veľmi malá, a aj v prípade swapovania na disk sa odtiaľ načítajú naspäť v zlomku sekundy. Výnimkou sú z toho rôzne unikátne stĺpce s veľkým počtom riadkov, ako napr. ID transakcie, ale takéto stĺpce chcú užívatelia vidieť len raz za čas. A aj tie sa dajú zoptimalizovať tak, aby nezaberali veľa miesta v pamäti. To však vedia už iba tí najlepší Jedi Mastri 🙂
Autor, tréner a expert na PowerPivot, Power BI a jazyk DAX. Založil som tento web, aby som pomohol dostať PowerPivot a Power BI do širšieho povedomia, a aby som ľuďom ukázal, že aj komplexné analytické problémy idú riešiť jednoducho. Po nociach vzývam Majstra Yodu a tajne plánujem ovládnutie vesmíru.